Search
7 min readSift: Local Hybrid Search Without the Infrastructure Tax
sift is a daemonless, single-binary local search tool that runs a full BM25 + vector + reranking pipeline on demand — no indexing service, no cloud dependency, built for agents and developers who need fast, repeatable retrieval over real corpora.
2026-03-10
sift is a local Rust CLI for document retrieval. Point it at a directory, ask a question, and it runs a full hybrid search pipeline - BM25, dense vector, fusion, optional reranking - and returns ranked results. No daemon. No background indexer. No cloud. One binary.
It's built for agents and developers who need reliable, repeatable search over raw codebases, docs, and mixed-format corpora without spinning up infrastructure to get there.
You can install it now on Mac, Windows & Linux. Source and build notes are at github.com/rupurt/sift.
The retrieval pipeline
Every query runs through four stages:
- Expansion — query variants are generated to broaden recall before retrieval begins.
- Retrieval — BM25 (keyword), phrase match, and dense vector retrieval run against the corpus. Each method captures different signal.
- Fusion — results are merged using Reciprocal Rank Fusion (RRF), balancing signal across retrieval methods without manual weight tuning.
- Reranking — optional local LLM reranking via Qwen applies semantic disambiguation on the fused candidate set.
Each stage is independently tunable. If you only need BM25 speed, skip the vector pass and reranker. If you want best-possible precision, run the full stack.
Architecture
The implementation is split into domain and adapters: domain objects model search plans, candidates, and scoring outputs; adapters implement the concrete BM25, phrase, vector, and reranking backends. A shared search service executes the same strategy model for CLI, benchmark, and eval flows — nothing changes between a dev run and a CI eval pass.
Performance is local-first by design:
- SIMD-accelerated dot-product for vector scoring on CPU-heavy workloads.
- Zig-inspired incremental cache — a two-layer design borrowed from Zig's build system. A manifest store tracks filesystem metadata (inode, mtime, size) mapped to BLAKE3 content hashes, so
siftknows exactly which files have changed without re-reading them. A content-addressable blob store holds pre-extracted text, pre-computed BM25 term frequencies, and pre-embedded dense vectors — meaning repeat queries never touch the neural network at all. Identical files across different projects share a single blob entry. The result: search performance bounded by dot-product speed, not inference latency. - Per-query embedding reuse across multi-stage pipelines.
- Mapped I/O and tight tokenization hot loops to keep latency low on large corpora.
One concrete tradeoff during development: lowering embedding max_length from 48 to 40 recovered latency budget while keeping quality above the BM25 baseline — a good example of how evidence-driven tuning beats guesswork.
The full internals are documented in ARCHITECTURE.
Evaluation
The numbers below are from a comparative strategy run over 5,185 SciFact documents (~7.8 MB) on an AMD Ryzen Threadripper 3960X. Each strategy is measured on retrieval quality (nDCG@10, MRR@10, Recall@10) and latency (p50 ms).
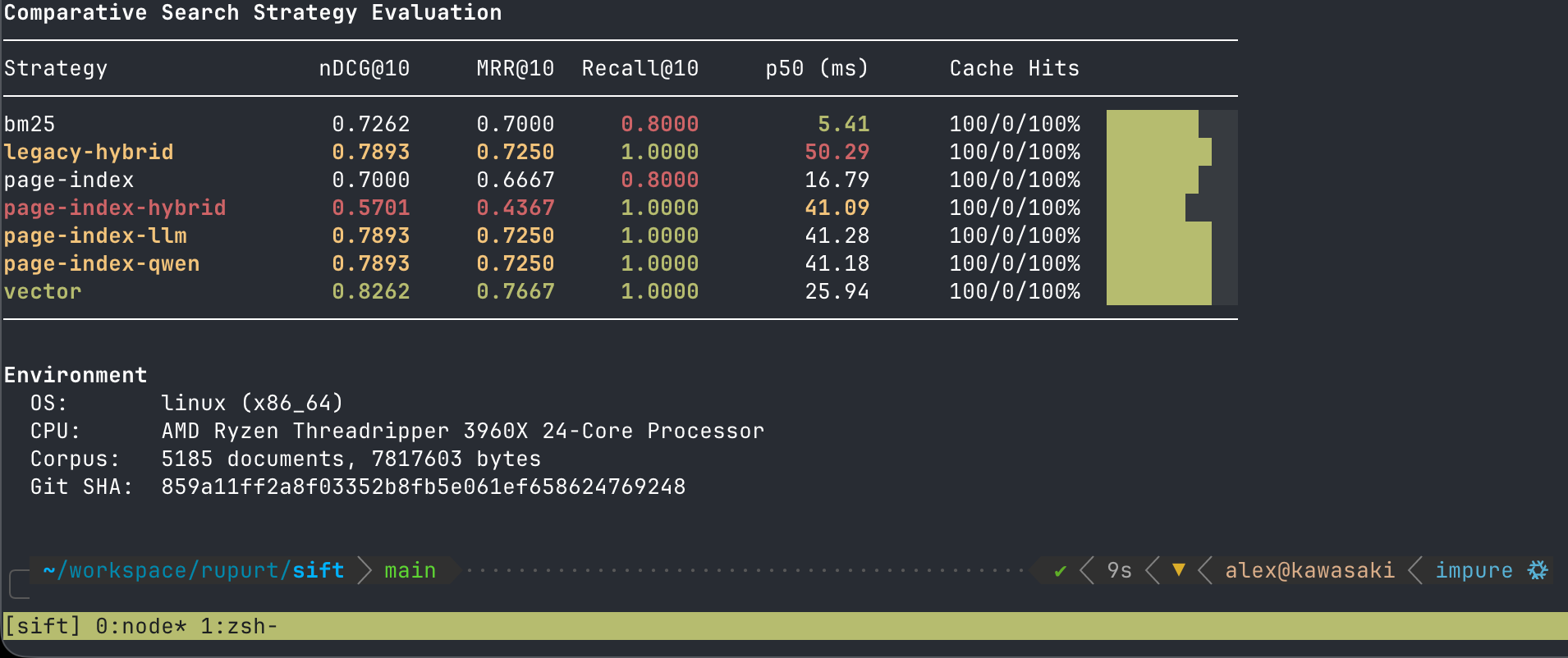
A few things worth noting from this run:
- BM25 is fastest at 5.41ms p50 — a strong default for latency-constrained cases where keyword recall is sufficient.
- Vector achieves the best nDCG@10 (0.8262) and perfect recall at 25.94ms — the most balanced strategy for most workloads.
- LLM reranking (page-index-llm, page-index-qwen) matches legacy-hybrid quality at comparable speed, which validates the local Qwen path as a practical alternative to heavier hybrid pipelines.
- page-index-hybrid is the only strategy that underperforms BM25 on nDCG — a useful reminder that adding complexity doesn't always improve quality.
Cache hit rates (100/0/100%) confirm the caching layer is working correctly across all strategies. Verbose output (-v, -vv) surfaces these rates, phase timings, and ranking metadata directly in the CLI — enough observability to diagnose retrieval issues without external tooling.
Why this matters for agents
For agents, latency and reliability are requirements, not nice-to-haves. Tooling loops fail hard when search is slow, drops context, or depends on services that may be unavailable.
sift removes that friction: retrieval is local, deterministic, and cheap to repeat. No daemon to health-check. No embedding service to rate-limit against. No cloud dependency to manage. The binary is self-contained and ships with release automation for Homebrew and a static Linux artifact path, so agents can rely on a pinned version without environment drift.
It is opinionated in the right direction: one binary, local-first by default, with explicit quality and evidence guardrails around every architectural change. That combination is rare in search tooling and unusually practical for day-to-day AI workflows.
How it was built
This shipped in a focused, nearly uninterrupted 24-hour push — implementation, eval design, benchmarking, performance tightening, packaging, and release prep handled in one sustained flow. Every major unit had acceptance criteria and measurable evidence attached before it was marked done.
What made that pace possible is something I'm not ready to talk about in detail yet. But sift is the first real proof that it works at speed, under real constraints, without cutting corners. More on that soon.
To get started, read the docs in README, CONFIGURATION, and EVALUATION, then tune strategy and model settings against your actual corpus. The architecture scales cleanly from fast BM25 keyword search to full hybrid retrieval with local reranking — no separate platform required.
Code is here: github.com/rupurt/sift.